45강. 왜 NoSQL인가?
기본적으로 관계형 데이터베이스와 이를 바탕으로 SQL이라는 분석쿼리언어로 데이터를 활용하여 비즈니스 문제를 해결할 수 있다.
그러나 데이터의 양이 많아지고, 동시에 그 데이터를 "탐색"해야하는 경우가 많아진다면?
가령 '이 고객에게 어떤 영화를 추천해야 하는지' 혹은 '이 고객이 과거에 어떤 웹 페이지를 방문했는지' 등의 특정 질문에 대한 답을 신속하고 빠르게 처리해야한다면?
이런 경우에 대비해서 NoSQL이 등장한 것이다.
NoSQL = Not only SQL = 비관계형 데이터베이스
- 수평적 확장성이 크다
- 빠르다
- 실패회복성도 갖춤
사용해야 하는 경우
- 대용량 데이터 세트에 주어지는 아주 간단한 질의에 대한 답을 빠르게 찾아야 할 때
- 해당 강의에서는 '행성만한 데이터에 무작위로 접근해야할 때' 라고 표현.
- 데이터가 증가하는 속도가 빠르므로 이에 대처하기 위해 단일 RDBMS는 한계가 있다. 분산 클러스터를 통해 수평적으로 확장하여 대응해야한다.
- 그럼에도 불구하고 RDBMS를 사용해야 한다면???(<- 하지만 이건 결국 빅데이터를 다루는 것에 비효율적인 대응책)
- 비정규화 : 참조(join)을 최소화하여 디스크 검색 시간 줄이기
- cashing service : memcashed 등의 인메모리 캐시레이어가 대표적, DB 접근에 대한 트래픽 최소화 but 캐시와 db간의 동기화가 안되는 경우 발생
- master/slave set-up : 쓰기와 읽기 역할을 분리
- Sharding : 각 파티션이 주어진 범위의 키를 처리
- materialized views : 서비스가 필요한 대로 데이터 화면을 구체화
- removing stored procedures
- 즉 RDBMS는 빅데이터 보다는 분석시스템에 좀 더 효율적
- 실제로 서비스 활용을 위해 데이터 조회에 사용되는 쿼리는 한정적
- 간단한 api로 데이터 조회 가능
- 결국은 일종의 키-값 데이터 저장소에서 데이터를 조회하는 형태로 데이터가 활용될 것
- 그럼에도 불구하고 RDBMS를 사용해야 한다면???(<- 하지만 이건 결국 빅데이터를 다루는 것에 비효율적인 대응책)
NoSQL의 구조

일정한 범위의 키별로 파티션해서 지정한 키에 대한 정보를 찾을 수 있는 시스템.
각 파티션 내에서 작업을 하고 만약 그 파티션 중 일부가 다운되더라도 백업시스템이 존재하여 정보나 서비스를 보존할 수 있다.
- 가령 특정 고객아이디가 주어진다면 db의 인스턴스에서 해당 키에 대한 정보를 찾으라고 지시하면 된다.
- 만약 데이터가 더 늘어나면 또 다른 샤드를 더해서 필요한 데이터를 업데이트 하면 된다.
확장성과 간단함이 핵심
대용량 데이터를 신속하게 처리하려면 그 과정이 최대한 간단해야 한다.


✅ 아마존 같은 웹 사이트의 웹서버를 데이터 소스로 가지고 있다면 해당 데이터를 위 그림처럼 hadoop 클러스터를 이용해서 처리할 수도 있다. spark streaming이나 flumer같은 기술을 사용해서 서버에 송신하는 데이터를 수신하고 동시에 프론트 엔드에 필요한 양식으로 데이터를 변환해서 mongoDB 등에 저장한다.
즉 실제 서비스에서도 hadoop 의 분산 시스템을 기반으로 데이터를 신속하게 처리할 수 있다.
즉 사용 목적에 맞게 데이터베이스를 디자인해서 활용하면 된다.
46강. HBase란 무엇인가?
hdfs위에 구축되어 있다.
hdfs에 의해 대용량의 데이터 세트를 저장했다면 hbase를 사용해서 그 데이터를 외부로 전송하여 활용할 수 있게 한다.
- hdfs 위에 구축된 확장 가능한 비관계형 데이터베이스이다.
- 쿼리언어를 가지고 있지 않다.(NoSQL 솔루션의 기본적인 특징)
- 대신 '이 키의 값이 무엇이고, 이 값을 키에 저장하기' 의 기능을 신속하게 제공하는 API가 있다.
- CRUD
- 기본적인 생성/읽기/업데이트/삭제와 같은 기본기능만 제공하지만 대량의 데이터를 굉장히 신속하게 처리할 수 있다.
- 구글의 big table 데이터베이스 이론을 기반으로 함
구글의 Big table 데이터베이스 이론
- 당시 구글은 전 세계의 웹페이지 링크정보를 저장하는 것에 어려움을 겪고 있었다. 즉 빅데이터 문제.
- 수십 페타의 데이타를 저장하더라도 일반적인 읽기나 쓰기의 경우 한자리 ms (~9ms)내의 응답성을 보장하기 때문에 빅데이타 핸들링에 매우 유리하며, 안정적인 구조로 서비스가 가능하다. 빠른 응답 시간 때문에 앞단에 캐쉬 서버를 두지 않아도 되서 전체 시스템 아키텍쳐를 단순화할 수 있는 장점을 가지고 있다.
- hbase는 big table에 기술된 알고리즘과 시스템을 적용한 오픈소스 데이터베이스이다.

- Region server는 일종의 키의 범위이다. 즉 샤드나 파티션과 같은 개념인 것이다.
- 데이터의 양이 늘어나면 데이터를 다시 파티셔닝한다.
- 데이터를 서버 클러스터에 자동 분산한다.
- 웹 애플리케이션이 데이터를 활용하기 위해 Hbase와 통신할때는 각각의 region server와 통신하고, 마스터 서버에는 데이터의 스키마를 기록한다.
- 주키퍼는 이러한 마스터 서버가 어떤 것인지 추적한다. 만약 마스터 노드가 다운되면 주키퍼가 차기 마스터를 결정하고 그 사실을 전체 시스템에 전달한다.
Hbase의 데이터 모델
- Row 기반
- 각 행은 고유의 키로 식별한다.
- 고객 정보 데이터베이스가 있다면 각 행은 고유한 고객ID 키로 식별할 수 있다.
- 관계형 데이터베이스와 비교하면 이것은 곧 프라이머리키로 볼 수 있다.
- 각 행마다 column family 개념이 잇다.
- 고정된 열세트가 아닌 많은 수의 열을 포함하고 있다.
- 그러나 일대일 매핑을 해도 상관 없다.
- 행과 열의 교차점에 형성되는 셀이라는 개념 존재
- 여러 버전으로 가질 수 있다.
- 타임스탬프 기준으로 저장하게 되고 이말은 데이터베이스 테이블 내 각 셀의 과거 버전을 저장하는 것이다.
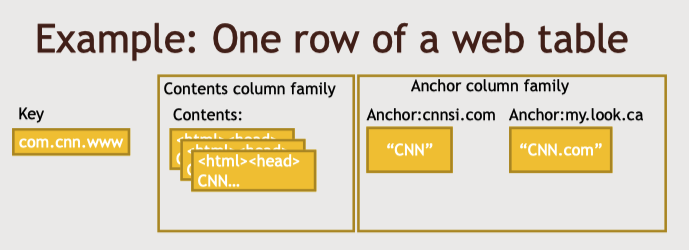
웹 페이지 혹은 웹사이트가 키이다.

AVRO와 Thrift 같은 프로토콜 버퍼들은 데이터를 간결하게 표현할 수 있다.
바이너리 양식을 사용하기 때문에 데이터를 더 효율적으로 저장하고 더 신속하게 결과를 구한다.
간단하게 하려면 REST 사용, 최대 성능을 원한다면 Thrift나 Avro
47강. 실습
-영화 평점을 Hbase로 가져오기
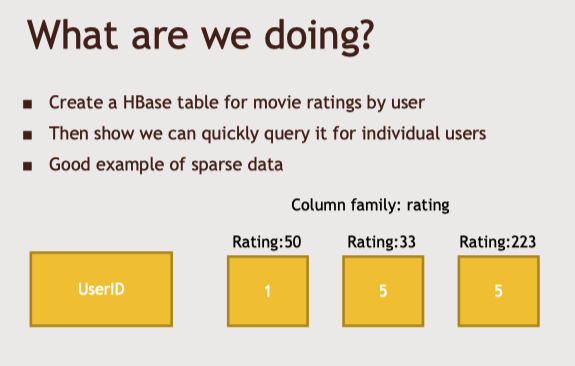

-> A라는 유저 기준으로, ID 50인 영화에는 1점을, 33인 영화에는 5점을 주었다는 것을 알수 있는 Hbase 구성
-> 실제 데이터를 저장하는 HDFS 파일 시스템 위에 HBase가 위치하고, 그 HBase 위에 REST 서비스를 실행한다.
-> HBase 지역서버를 데이터를 저장하는 HDFS 서버에서 실행하면 이상적이다. 그러면 데이터 국소성을 갖고 불필요한 네트워크 전송을 피할 수 있다.
Python Script 파일 예시
from starbase import Connection
c = Connection("127.0.0.1", "8000")
ratings = c.table('ratings')
if (ratings.exists()):
print("Dropping existing ratings table\n")
ratings.drop()
ratings.create('rating')
print("Parsing the ml-100k ratings data...\n")
ratingFile = open("e:/Downloads/ml-100k/ml-100k/u.data", "r")
batch = ratings.batch()
for line in ratingFile:
(userID, movieID, rating, timestamp) = line.split()
batch.update(userID, {'rating': {movieID: rating}})
ratingFile.close()
print ("Committing ratings data to HBase via REST service\n")
batch.commit(finalize=True)
print ("Get back ratings for some users...\n")
print ("Ratings for user ID 1:\n")
print (ratings.fetch("1"))
print ("Ratings for user ID 33:\n")
print (ratings.fetch("33"))
ratings.drop()
48강. 실습
- HBase를 Pig와 함께 사용하여 대규모 데이터 가져오기
- 위의 실습에서 활용한 파이썬은 실제 빅데이터에서는 효율적이지 못하다. 따라서 실제로 hadoop echo system기반으로 pig를 사용하여 실습을 해본다.

- HBase 테이블이 사전에 만들어져 있어야 한다.
- 셸로 접속해서 테이블을 먼저 구성하고, 첫째 열에는 고유한 키를 가져와야한다.
- Pig에서 이런 관계성을 스트립트의 각 라인에 만들고, 이러한 관계성은 고유한 키를 가져서 HBase 테이블에 저장할 열과 매핑할 열을 갖도록 한다.
- USING, STORE 절 활용
- HBase의 행은 트랜잭션이 가능하므로 Pig 작업과 관련된 수많은 매퍼들이 있다.
클러스터에 병렬적으로 작업되어서 동시에 기록하며 서로 부딪히는 상황을 걱정할 필요가 없다?
Pig 스크립트 파일 예시
users = LOAD '/user/maria_dev/ml-100k/u.user'
USING PigStorage('|')
AS (userID:int, age:int, gender:chararray, occupation:chararray, zip:int);
STORE users INTO 'hbase://users'
USING org.apache.pig.backend.hadoop.hbase.HBaseStorage (
'userinfo:age,userinfo:gender,userinfo:occupation,userinfo:zip');
49강. Cassandra 개요
- cassandra - NoSQL with a twist
- 분산 시스템이나, 마스터 노드가 없어서 단일 실패지점이 없다.
- Bigtable이나 HBase와 동일한 데이터 모델과 구조
- 비관계형 데이터 베이스 - 데이터 결합이나 정규화 불가
- 트랜잭션 쿼리에 최적화
- 고가용성, 거대한 처리량, 고확장성을 목표
- CQL이라는 자체 쿼리 언어 보유
- 쿼리언어가 있음에도 NoSQL로 처리하는 이유는 기본적으로 비관계형이기 때문
- 데이터를 프라이머리키로 나누어서 클러스터에 분산
Cassandra's Design Choices
- CAP 이론
- 일관성(consistency), 가용성(availability), 파티션 지향성(partition tolerance)
- 이 셋 중에 두가지만 가질 수 있음.
- 일관성 : 데이터베이스에 무언가를 작성했을 때 무슨일이 있어도 나중에 응답을 받는다. 해당 개념은 카산드라가 제공하는 궁극적 일관성이라는 개념과 맞바꿀 수 있다. 어떤 값을 작성 했을 때 값이 1~2초 정도 돌아오지 않아도 괜찮다는 개념
- 가용성 : 데이터베이스가 항상 작동하여 신뢰할 수 있고 많은 예비 데이터를 구축해 놓음
- 파티션 지향성 : 데이터가 쉽게 나눠지고 클러스터에 분산될 수 있음.
- 모든 데이터베이스가 데이터를 분산하지는 않는다.
- 여기서 하둡은 파티션 지향성을 절대 포기할 수 없다. 클러스터에 데이터를 분산하려면 꼭 필요한 요소이다.
- 카산드라도 분산 저장 서비스인 만큼 파티션 지향성을 꼭 가지고 간다면, 일관성과 가용성 중에 선택할 때 가용성을 우선시한다.
- 무언가를 카산드라에 작성하면 그 결과를 즉각적으로 받지 못한다. 클러스터 전체에 변화를 전파해야 하기 때문이다.
- 즉 조정가능한 일관성이라고 한다.
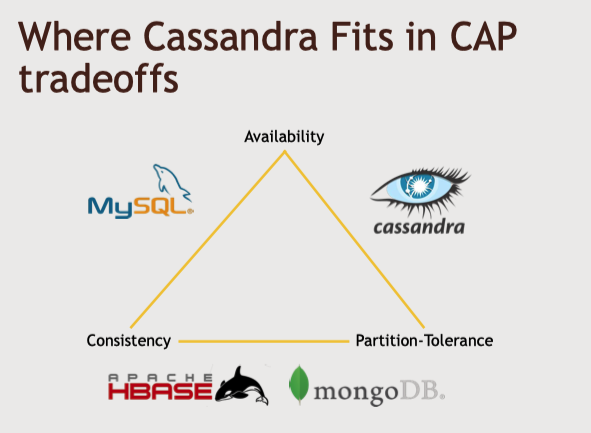
여기서 카산드라는 쿼리의 일부로 가용성과 일관성 사이에서 균형을 조정할 수 있다.
해답은 카산드라의 구조에서 찾을 수 있다.
Cassandra architecture
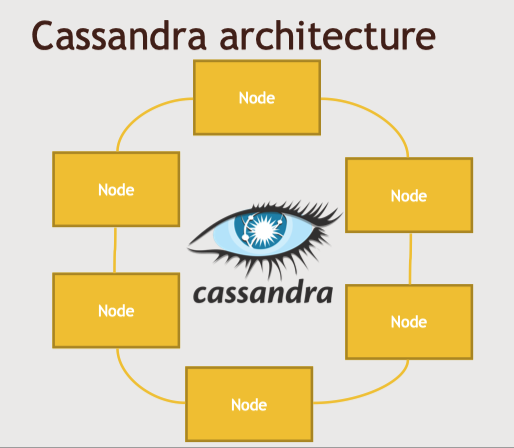
어떤 노드가 어떤 데이터를 갖는지 추적하는 마스터 노드가 없다.
가십프로토콜을 사용해서 클러스터의 모든 노드는 매초마다 서로간에 소통하며 누가 어떤 데이터를 가지고 어디에 복사본이 잇는지 추적한다.
즉 카산드라 클러스터의 모든 노드는 똑같은 소프트웨어를 실행하고 똑같은 일과 기능을 한다.
클라이언트는 이중 아무 노드와 소통하여 데이터가 어디 있는지 알아낼 수 있다.
노드들은 서로 소통하며 데이터를 복사하고 클러스터 구성 시 지정한 중복 수준에 따라서 모든 노드가 백업 복사본을 가질지 결정한다.
클라이언트가 어떤 데이터를 특정 노드에 기록 -> 해당 노드에서 데이터의 일정 부분을 해시 -> 지정한 노드에 매핑 -> 백업으로 다른 노드에 매핑 -> 구성에 따라 세번째까지 매핑 가능
이러한 구조에서 카산드라가 일관성을 조정하기 위해서 적어도 몇개 이상의 노드에서 같은 값이 나와야 한다고 설정할 수 있는 것이다.
카산드라와 하둡클러스터를 통합
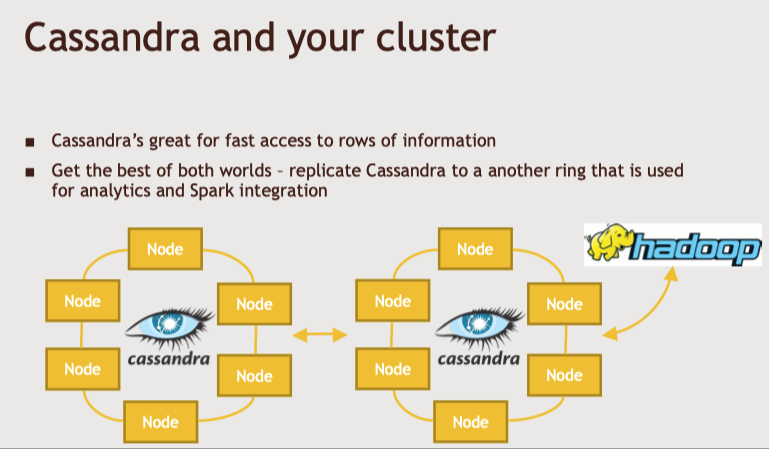
카산드라 노드에 별도의 랙과 데이터 센터 구성.
카산드라는 이를 인지하고 그 사이에서 복사본을 관리.
이를 또 다른 클러스터에 복사할 수도 있다.
같은 데이터를 A라는 클러스터에서 B라느 클러스터로 가져와서 분석에 사용할 수 있다.
그리고 이 복사본을 원본 클러스터와 통합한다.
그러면 hive나 spark로 일괄 지향 시스템 혹은 분석 시스템에서 데이터를 분석할 수 있다.
이렇게 하면 트랜잭션 시스템의 성능에 영향을 주지 않고, 분석을 할 수 있다.
CQL
- 프라이머리키를 기반으로 읽기와 쓰기를 하는 카산드라 API이다.
- No Join
- 비정규화된 데이터
- CQLSH, SQL 셸이라는 도구 사용
- 명령줄 사용, 상호적 도구를 사용해 테이블을 생성하거나 뭐가 어디 있는지 탐색하는데 사용
- Mysql의 데이터베이스의 개념이 카산드라의 키스페이스 개념으로 사용
cassandra와 spark
- 함께 사용하기 수월하다.
- dataframe에 쿼리하면 카산드라 클러스터의 CQL쿼리로 번역된다.
- 카산드라에 저장된 데이터를 스파크로 분석하거나/ 외부에서 들어오는 데이터를 스파크가 가공해서 카산드라에 저장하는 방식으로 둘을 결합해서 사용할 수 있다.
51~52강. 실습
- cassandra 설치(강의 영상참고)
- spark 출력을 카산드라에 쓰기
from pyspark.sql import SparkSession
from pyspark.sql import Row
from pyspark.sql import functions
def parseInput(line):
fields = line.split('|')
return Row(user_id = int(fields[0]), age = int(fields[1]), gender = fields[2], occupation = fields[3], zip = fields[4])
if __name__ == "__main__":
# Create a SparkSession
spark = SparkSession.builder.appName("CassandraIntegration").config("spark.cassandra.connection.host", "127.0.0.1").getOrCreate()
# Get the raw data
lines = spark.sparkContext.textFile("hdfs:///user/maria_dev/ml-100k/u.user")
# Convert it to a RDD of Row objects with (userID, age, gender, occupation, zip)
users = lines.map(parseInput)
# Convert that to a DataFrame
usersDataset = spark.createDataFrame(users)
# Write it into Cassandra
usersDataset.write\
.format("org.apache.spark.sql.cassandra")\
.mode('append')\
.options(table="users", keyspace="movielens")\
.save()
# Read it back from Cassandra into a new Dataframe
readUsers = spark.read\
.format("org.apache.spark.sql.cassandra")\
.options(table="users", keyspace="movielens")\
.load()
readUsers.createOrReplaceTempView("users")
sqlDF = spark.sql("SELECT * FROM users WHERE age < 20")
sqlDF.show()
# Stop the session
spark.stop()Reference
https://velog.io/@koo8624/%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4-Google-Bigtable
'DE > Study' 카테고리의 다른 글
| [Hadoop_기초] Udemy course - 섹션 7-1. Drill & Phoenix (0) | 2022.07.17 |
|---|---|
| [Hadoop_기초] Udemy course - 섹션 6-2.MongoDB & 데이터베이스 선택하기 (0) | 2022.07.12 |
| [Hadoop_기초] Udemy course - 섹션 5.Hive (0) | 2022.06.26 |
| [Hadoop_기초] Udemy course - 섹션 4.Spark (0) | 2022.06.19 |
| [Hadoop_기초] Udemy course - 섹션 3.Pig (0) | 2022.06.06 |