DW raw_data스키마 구성하는 사례

-> 데이터 파이프라인을 통해 왼쪽의 데이터들을 raw_data에 복사함.
-> 각 테이블에 따라 파이프라인이 테이블마다 하나씩 존재
RDS 뿐 아니라 앰플리튜드 데이터도 DW에 적재해서 같이 분석할 수 있도록 해야한다
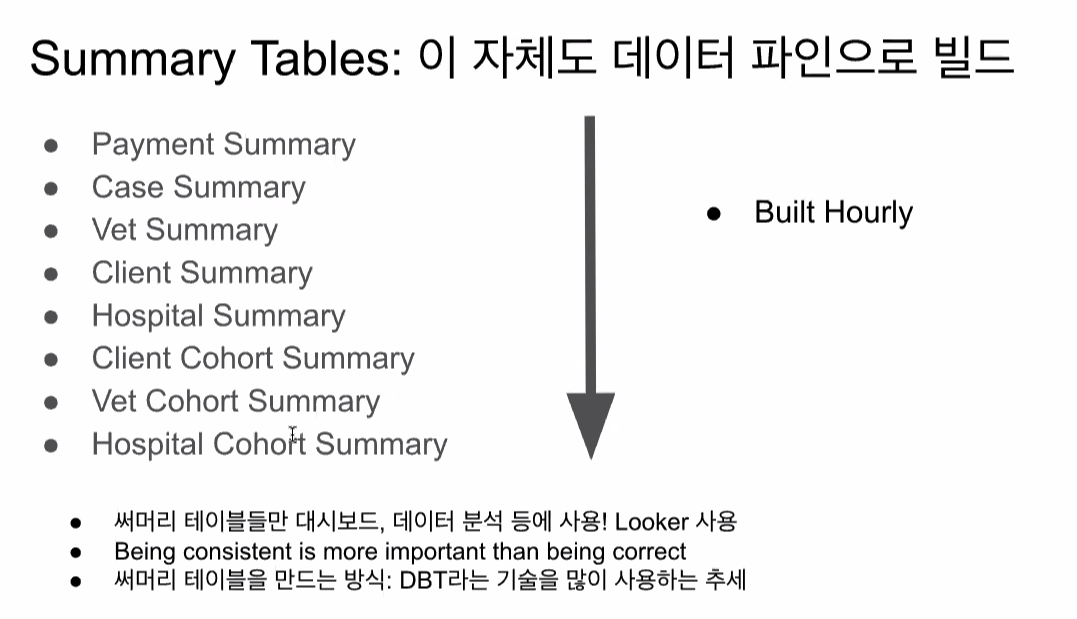
-> 이런 raw_data에서 DW 내의 summary table스키마로 별도 데이터 파이프라인 빌드
(원하는 형태로 포맷을 바꿔줌. 쿼리 효율화를 위해)
-> 분석할 때는 서머리 테이블만 쓴다
-> 배치 잡들은 보통 30분마다
->DW에서는 프라이머리키가 보장안되므로 포맷할때 DE가 보장할 수 있도록 작업해야 한다.
SQL
SQL이 여전히 중요한 이유?
오래 전에 생겨서 안정적
구조화된 데이터 다룰 때 좋다. 테이블 형태로 데이터를 저장할 수만 있으면 SQL로 다 처리할 수 있다.
하둡의 맵리듀스가 등장하면서 비교(하둡의 맵리듀와 SQL 좀 더 공부)
단점은?
구조화되지 않은 즉 로그 데이터를 처리할 때는 좋지 않다. DB에 따라 SQL syntax가 조금씩 다르다
sqprk이 프로그래밍화된 구조화된/구조화되지 않은 데이터를 모두 다 처리 가능(spark 공부 필요) -> 이건 대량 데이터인 경우
현업에서 주의할 것
데이터를 믿지말고 의심할 것.
실제 데이터를 일일이 살펴볼 것 (노가다)
데이터 품질 체크
-> 중복된 레코드 체크
-> 최근 데이터 존재여부 체크
-> primary uniqueness 체크
-> 값이 비어있는 컬럼 체크
-> 위의 경우도 unit test로 만들어서 체크해볼 수있다.
-> 데이터가 많아지므로 각 테이블의 중요도와 비즈니스 밀접도를 잘 파악해야함
-> 테이블과 데이터 파악이 우선이다. 후에 중복된 요약 테이블이 만들어질 수 있다 (데이터 디스커버리 오픈소스 Datahub/Amundsen 등을 활용)
SQL 문법
다수의 쿼리문을 ;(세미콜론)으로 구분
DDL(테이블 구조 정의 언어) : 테이블 생성 같은 쿼리 VS DML(레코드 조작언어)
NULL은 불값과도 완전히 다르므로 잘 생각하고 where 조건 걸어야 한다. 즉 is true면 null 미포함


'DE > Study' 카테고리의 다른 글
| 프로그래머스[데이터 엔지니어링 스타터 키트]필기 : Airflow 심화 (0) | 2022.01.05 |
|---|---|
| 프로그래머스[데이터 엔지니어링 스타터 키트]필기 : ETL&Airflow (0) | 2021.08.28 |
| 프로그래머스[데이터 엔지니어링 스타터 키트] 필기 : AWS&Cloud&Redshift 간단한 개념 (1) | 2021.08.19 |
| 프로그래머스[데이터엔지니어링 스타터키트]필기 : 데이터팀과 데이터 엔지니어 (0) | 2021.08.10 |
| [DE NanoDegree PR 0] what is Data Engineering (7) | 2021.08.05 |