53강. MongoDB 개요
mongoDB는 다른 오픈소스로 제공되는 데이터베이스 시스템과 달리 기업 차원에서 개발 및 지원되고 있다.
mongoDB는 거대하다는 뜻의 humongous에서 유래되었다.
Mongo DB의 특징
- mongoDB의 핵심은 빅데이터를 다룬다는 것만이 아니라 문서형 데이터 모델을 갖고 있다는 것

- 구조화될 필요가 없다.(No Schema)
- 저장되는 문서마다 같은 스키마를 가질 필요도 없다.
- cassandra와 다른 점은 고유식별자가 필요하지 않다. mongoDB는 자동으로 ID필드를 만들고 PK처럼 사용한다.
- 만약 sharding을 하고 싶다면 색인을 만들 수 있다.
- 검색이나 쿼리를 위해 유연하게 색인할 수 있다.
- 데이터 구조 즉 스키마는 필요없지만 색인을 위해서는 미리 고민할 필요가 있다.
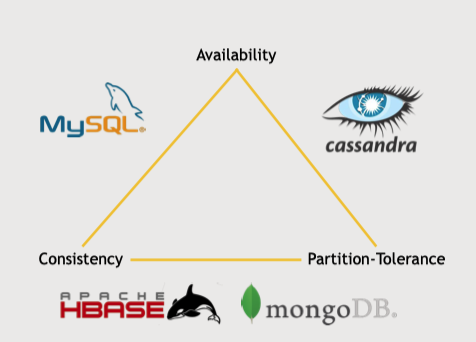
- CAP 정리에서 consistency(일관성)과 partition-tolerance(분산형)의 특징을 지님
- 단일 마스터노드와 소통하며 일관성을 유지하는 것을 우선시한다.
- 따라서 해당 단일 마스터노드가 다운되면 새 마스터 노드를 구성하는 동안 비가동 주기가 생긴다. 해당 상태에서는 read는 가능하지만, 완전히 해결될 때까지 write는 비활성화된다.
- join을 할 수 없으므로 저장되는 데이터가 비정규화되어야 한다.
- join을 하지 않는 대신에 관련된 서브데이터를 도큐먼트 내부에 넣는다.
- 데이터베이스란 테이블과 행이 아니라 컬렉션과 문서이다.
- 테이블과 달리 컬렉션에는 거의 모든 것이 들어갈 수 있다.
- 데이터를 다른 데이터베이스의 컬렉션으로 옮길 수 없다.
- 하나의 json이 mongodb에서 도큐먼트이다.
- 기업을 대상으로한 솔루션
- 메모리맵 형태의 파일엔진이라 메모리에 의존적이다.
- 메모리 크기가 성능을 좌우
- 트랜잭션이 필요한 서비스 데이터베이스로는 적합하지 않으며, 쌓아놓고 삭제가 없는 로그데이터나 세션 같은 경우에 적합
MongoDB의 구조(아키텍쳐)
Replica Set - 내구성과 관련(빅데이터와 관련된 확장성과는 관련되어있지 않다.)
mongoDB는 단일 마스터 아키텍쳐임에 따라, 마스터 db의 복사본을 일정 시간동안 유지하는 secondary db(백업 복사본)를 가진다.
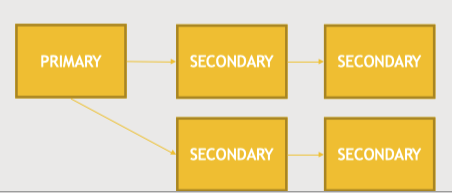
마스터노드에 쓰기 작업을 하면 작업 로그를 통해 쓰기 작업이 복제되고 secondary 노드에 전달된다.
실제로 위와 같이 하나의 마스터 노드에 여러개의 secondary 노드가 있을 수 있다.
마스터 노드가 다운되면 이들 중 하나가 마스터노드가 되는 것이다.
secondary node가 대체되는 단계
- 사용자가 특정한 동기화 소스를 사용하라고 요청했는지 확인 : 'replSetSyncFrom' 명령어로
- 지정한 소스로부터 동기화하거나 모든 노드를 반복하며 컨디션을 확인하면서 조건을 만족하는 노드를 선택
- 이 때 동기화 체인이 비활성화 되어있다면 노드들은 마스터 노드와만 동기화한다.
장점
- 기존 마스터 노드가 다운되었을때 다른 마스터 노드로 대체되는 시간이 매우 짧다. 즉 빠르게 진행된다.
단점
- 과반수 이상의 서버가 누가 차기 마스터 노드가 될지 동의해야한다.
- 이를 위해서는 홀수의 서버만 가질 수 있다.
- 적어도 세개의 서버를 가지게 된다.
- 즉 비용적인 부담이 생긴다.
- 이를 위해 arbiter(결정권자)노드를 가질 수 있다.
- 작업하는 애플리케이션이 mongodb의 마스터 노드 뿐 아니라 세컨더리 노드도 일부 알고 있어야 한다.
- 이에 따라서 데이터센터의 변경이 생겨서 세컨터리 노드가 추가되거나 제거될때 애플리케이션에도 알려야한다.
- 이는 mongodb 3.6에서 'DNS 시드 목록 연결 형식' (Seedlist Connection Format)로 해결된다.
- delayed secondary node(지연노드) 설정 가능
- 프라이머리와 세컨더리 노드 사이에 얼마 간의 딜레이를 설정했을 때의 개념
- 복제 과정에서 딜레이를 설정한 경우, 프라이머리 노드에 문제가 생겼을 때 지연 노드를 통해 이전에 가지고 있던 데이터를 신속하게 되살릴 수 있다.
Sharding - 확장성과 관련
작동하는 방식은 다수의 레플리카 세트를 가지고, 각 레플리카 세트가 데이터베이스 내 색인화된 값의 일정 범위의 값을 갖게 된다.
색인(Index)
이렇게 하려면 컬렉션의 고유한 값에 색인을 구성해야 한다.
색인은 여러 레플리카 세트에 걸친 정보의 양의 균형을 유지하고 각 애플리케이션 서버나 mongodb와 소통하는 시스템에 걸리는 부하도 조정한다.
이때 mongos라는 프로세스를 실행하고 이는 어디선가 실행되는 구성서버(config server)의 컬렉션과 소통한다.
- Mongos
다수 구성된 샤드의 인터페이스 역할을 한다. 클라이언트 요청을 올바른 샤드로 라우팅하는 것이 주요 기능이다.
config 서버의 메타데이터를 캐시한다.
빅데이터를 샤드 서버로 분산해주는 프로세스이다.
- config server
구성서버는 클러스터의 메타데이터, 구성 설정 등을 저장하는 서버이다.
동일한 역할을 담당하는 3대로 구성된다. 즉 fail-over를 위한 복제구조를 사용한다.
이들은 데이터를 취득하기 위해 능동적인 역할을 하지 않으므로, 데이터 동기화를 위해 mongos를 활용한다.
전체적인 서비스의 데이터 흐름에서 config server 가 크게 중요하지 않지만, mongos 입장에서는 중요한 서버이다.
이 컬렉션은 데이터베이스가 어떻게 파티션 됐는지 알고 있고 이를 사용해 어떤 레플리카 세트에 필요한 정보가 있는지 알아낸다.

- 각 웹서버의 프로세스는 mongos 인스턴스를 실행한다.
- 그리고 이 mongos 인스턴스는 어디선가의 config server(구성서버)와도 소통한다.
- mongos는 밸런서를 실행하기도 하는데, 이는 어떤 파티션 필드에 값들이 고르게 분산되어 있지 않다면 실시간으로 레플리카 세트를 재분배한다.
MongoDB 샤딩의 특징
- 자동 샤딩은 시간이 지남에 따라 균형을 맞추는 것에 가끔 실패하기도 한다.
- split storm : mongos 프로세스가 너무 자주 재실행 되는 상태
- 재분배가 이루어지지 않을수도 있다.
- 원래는 구성서버가 이를 감시하며 관리했으나 이 또한 수정됨.
- 구성서버를 레플리카 세트의 일부로 배치할 수 있다.
샤딩이 무조건적으로 장점만 지닌 것은 아니다.
- 샤딩은 복잡하기 때문에 샤딩된 클러스터를 유지하기 위해서는 사전 계획을 잘해야 한다.
- 분할된 컬렉션을 분할 해제할 방법이 없다.
- 기본적으로 전체 클러스터의 전체 성능에 영향을 준다.
- 샤딩 된 환경에는 몇가지 운영 제한이 있다.
- 샤드 키의 접두사가 없는 경우 mongos는 클러스터의 모든 샤드를 쿼리하는 브로드 캐스트 작업을 수행하므로 쿼리 작업이 오래 실행될 수 있다.
샤딩의 한계
- 원인을 알 수 없는 문제로 마스터 서버가 fail되어도 mongos는 스레드가 수행되기 전까지 여전히 fail된 서버를 마스터 서버로 간주할 가능성이 있다. 이에 따라 데이터 유실의 가능성이 존재한다.
- 샤딩된 하나의 청크에 저장할 수 있는 객체의 개수와 분할 지점의 갯수가 한정적이다.
MongoDB의 장점
- NoSQL데이터베이스의 기본적인 장점
- 모든 타입의 데이터를 저장
- 자바스크립트 인터프리터를 가진 셸을 사용할 수 있어서 자바스크립트 함수를 쉽게 실행할 수 있다.
- 여러 색인을 지원
- 그러나 샤딩을 위해서는 하나만 사용할 수 있다.
- 색인은 리소스를 많이 잡아먹음
- 대용량의 정보나 텍스트를 포함한 문서를 저장하는데에 효율적
- 지리공간 색인을 만들어서 위경도에 대한 검색도 가능
- 하둡을 대체하려고 함
- 내재된 집계 기능 존재
- 맵리듀스 코드도 실행가능
- GridFS라는 고유의 파일시스템을 갖고 있다.
- 많은 애플리케이션이 하둡파일시스템까지 가질 필요가 없을 때 좋은 제안이 될 수 있다.
- 따라서 하둡 에코시스템의 다른 기술들과도 결합 가능하다.
- SQL 커넥터 가능
54~55강. 실습
[54강] MongoDB 설치 및 spark와 mongodb 통합하기
강의에서는 ambari 활용
from pyspark.sql import SparkSession
from pyspark.sql import Row
from pyspark.sql import functions
def parseInput(line):
fields = line.split('|')
return Row(user_id = int(fields[0]), age = int(fields[1]), gender = fields[2], occupation = fields[3], zip = fields[4])
if __name__ == "__main__":
# Create a SparkSession
spark = SparkSession.builder.appName("MongoDBIntegration").getOrCreate()
# Get the raw data
lines = spark.sparkContext.textFile("hdfs:///user/maria_dev/ml-100k/u.user")
# Convert it to a RDD of Row objects with (userID, age, gender, occupation, zip)
users = lines.map(parseInput)
# Convert that to a DataFrame
usersDataset = spark.createDataFrame(users)
# Write it into MongoDB
usersDataset.write\
.format("com.mongodb.spark.sql.DefaultSource")\
.option("uri","mongodb://127.0.0.1/movielens.users")\
.mode('append')\
.save()
# Read it back from MongoDB into a new Dataframe
readUsers = spark.read\
.format("com.mongodb.spark.sql.DefaultSource")\
.option("uri","mongodb://127.0.0.1/movielens.users")\
.load()
readUsers.createOrReplaceTempView("users")
sqlDF = spark.sql("SELECT * FROM users WHERE age < 20")
sqlDF.show()
# Stop the session
spark.stop()[55강] MongoDB shell 사용하기
56강. 데이터베이스 기술 선택하기
데이터베이스에는 다양한 옵션이 있다.
MySQL, MongoDB, Cassandra, HBase 등에서 시스템 구축 시에 선택할 때 고려해야 할 사항들이 있다.
1. Intergration Considerations
어떤 시스템을 통합해야 하는가를 고려해야한다.
예를 들어 spark로 분석작업을 한다면 이와 쉽게 연결할 수 있는 데이터베이스를 고려해야 한다.
2. Scaling requirements
즉 확장에 필요한 요구사항을 고려해야한다.
얼마나 많은 데이터가 필요한가? 시간이 지나면 무제한으로 늘어나는가?
이러한 확장성과 더불어 처리량도 고려되어야함. 초당 얼마만큼의 요청을 처리해야 하는가?
이에 따라 처리 부담을 고르게 분산할 수 있는지도 고려해야한다.
3. Support considerations
데이터 베이스 관련해서 내부적으로 어떤 전문가들이 구성되어있는가?
가령 NoSQL을 회사에 도입하려 한다면, 해당 데이터베이스의 경우 정보보안에 취약하다. 따라서 이를 안전하게 구성해 줄 전문가가 필요한 것이다.
4. Budget considerations
비용고려
5. CAP considerations
일관성, 가용성, 분할 내성(분산성) 이 중 두 개를 골라야 한다.
하나의 서버로 구성할 수 없는 빅데이터를 다룬다면 분할내성은 필수이다.
시스템이 몇초에서 몇분동안 다운되어도 된다면 가용성은 필수가 아니다.
아니면 사용자가 항상 새로운 데이터를 일관되게 받아야 하는가? 아니면 몇 초동안은 이전 데이터 값을 받는 궁극적 일관성으로도 충분한가? 이러한 경우라면 일관성이 필수가 아니다.
세개 중에 두개를 우선시 한다고 다른 하나의 요소를 완전히 버리는 것은 아니다.
점차적으로 세 개의 요소를 다 충족하기 위해 각 데이터베이스마다 추가적인 기능들이 생기고 있다.
cassandra
가용성, 분할내성(분산, 파티션 지향성)을 고려하지만 사용자가 원하는 만큼 일관성을 구성할 수 있다.
가령 모든 레플리카에서 같은 결과를 받아야만 트랜잭션의 결과로 인정한다고 설정할 수 있다.
MySQL
샤딩을 구성해서 분할내성을 충족할 수 있다.
실제로 빅데이터를 다룰 것이 아니라면 NoSQL데이터 베이스보단 MySQL을 사용하는 것이 좀 더 간단하고 충분하다.
6. 구성의 단순함
Reference
'DE > Study' 카테고리의 다른 글
| [Hadoop_기초] Udemy course - 섹션 7-2. Presto (0) | 2022.07.26 |
|---|---|
| [Hadoop_기초] Udemy course - 섹션 7-1. Drill & Phoenix (0) | 2022.07.17 |
| [Hadoop_기초] Udemy course - 섹션 6-1.Hbase & Cassandra (0) | 2022.07.06 |
| [Hadoop_기초] Udemy course - 섹션 5.Hive (0) | 2022.06.26 |
| [Hadoop_기초] Udemy course - 섹션 4.Spark (0) | 2022.06.19 |