데이터 엔지니어링에 대해서 여러 자료들을 참고해서 공부중이지만, 너무 방대해서 가이드라인을 잡으면 좋겠다 생각했고 구글링을 했다. 그러다가 udacity를 알게되었고 직장을 다니면서 일정 자유롭게 강의를 들을 수 있을거 같아서 신청했다.
따라서 공부할 때마다 내용들을 블로그에 정리해보려 한다.
물론 프로그래머스 데이터엔지니어링 스터디도 신청해서 무리일까 싶었지만서도...?
데이터 엔지니어링은 데이터를 저장하고 organize하고 사용가능한 데이터를 만드는 것에 핵심적인 역할이다.
더 좋은 서비스를 만들고 고객들을 더 만족시키기 위해, 그리고 이를 위한 분석을 기반으로 한 데이터를 가공하고, 이를 전달하는 파이프라인을 설계하고 데이터베이스를 구축한다.

-> 즉, 깨끗하게 가공된 데이터를 전달하는 역할
-> 가장 중요한 것은 유저의 행위를 로깅하거나 sensor data를 추적하여 데이터를 수집
-> 데이터를 데이터 웨어하우스에 파이프라인을 통해 이동시키고 저장하는 것이다.
-> 그리고는 데이터의 정확성을 점검하고 가공하며 사용가능하게 변환한다(ETL)
-> 이러한 데이터를 모으고 라벨링함. 특정 모델링(AI, 딥러닝 등)을 위해

따라서 데이터를 저장하고 파이프라인을 활용하여 이동시키고, 서비스에 사용되기 위해 가공하는 부분에 대해서 집중적으로 공부
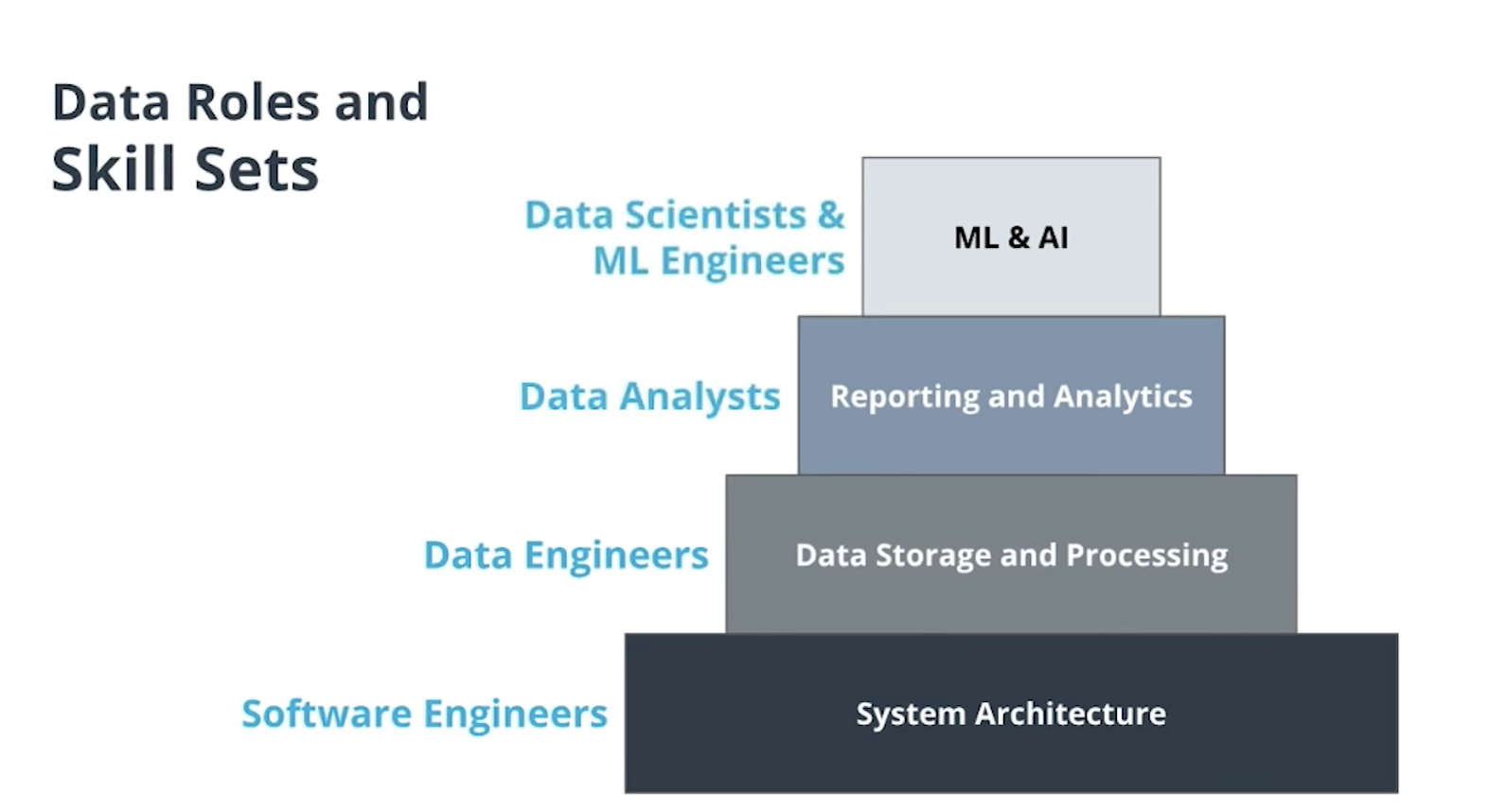
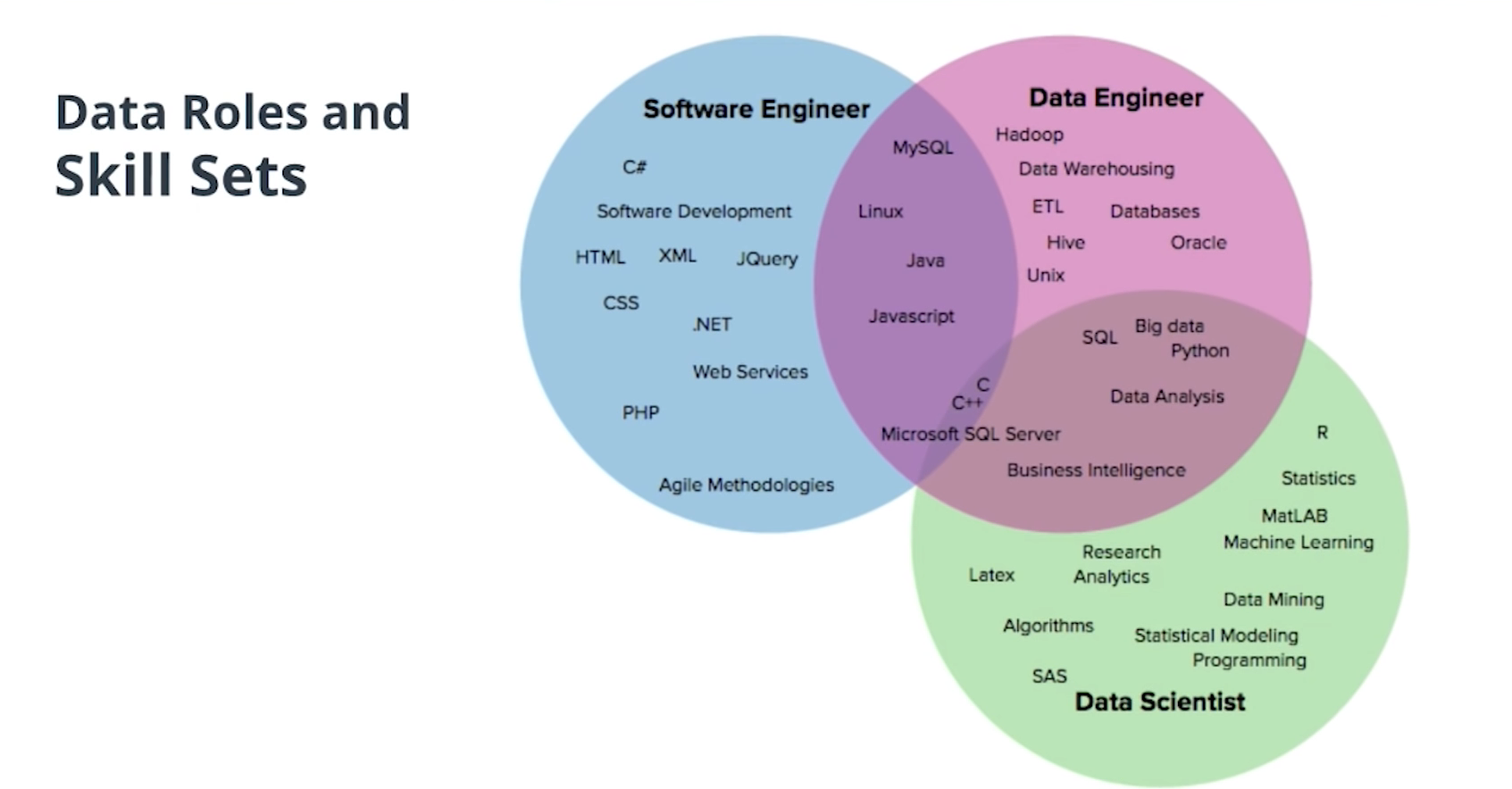

-> 일상적인 tasks 는 airflow를 통해서 데이터 파이프라인이 잘 작동하고 있는지 살펴보고, 이에 따라서 예상범위 내에서 데이터가 잘 축적되고 흐르고 있는 지를 계속 감시
-> 많은 데이터 소스와 행태와 불균등성 사이에서 일해야 하는것이 어려운 점이다. 그리고 이 많은 데이터가 파이프라인을 통해 잘 흘러가고 이를 통해 인사이트를 잘 얻을 수 있게 하는 것.
-> 너무 툴에 집착하지 마라/ 메인은 airflow, redshifts, spark, presto / 여러 회사와 산업군에서 넓게 활용할 수 있도록 핵심에 공부하도록 집중
-> 집중할 것은 데이터파이프라인을 어떻게 만들고 관리 할 것인가?
-> 많은 데이터를 어떻게 분석가능하게 만들 것인가?
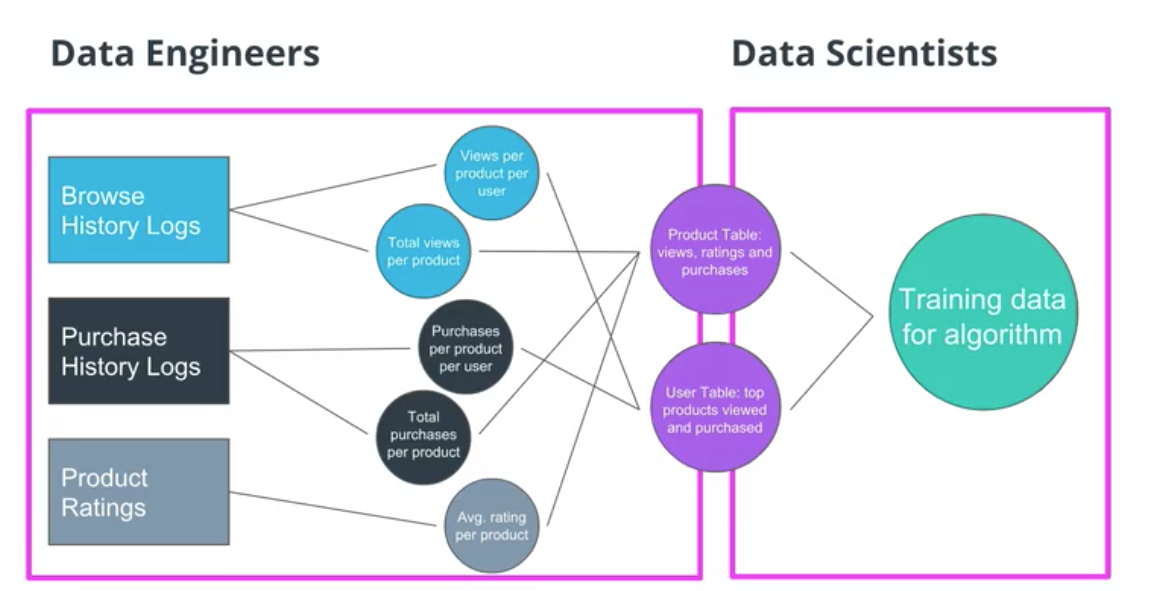
ON the evolution of Data Engineering
1. 빅데이터 : 특히 2006년에 하둡이 오픈소스로 공개되면서
2. 복잡해진 데이터 파이프라인 : 대표적으로 airflow가 이 기능을 함.
3. 머신러닝
4. spark & real-time : 실시간 데이터 처리
5. 데이터를 다루는 cloud 와 serverless 제품의 발전 : AWS의 람다를 통해 실제로 데이터또한 복잡한 인프라구조를 구축하지 않고 쉽게 데이터를 받아들여 저장할 수 있었다.
The role of the data engineer is no longer to provide support for analytics purposes but to be the owner of data-flows and to be able to serve data both to production and for analytics purposes.
Data Engineering Tools
The rise of DE: common skills and tools
- Hadoop
- Spark
- Python
- Scala
- Java
- C++
- SQL
- AWS/Redshift
- Azure
Data Engineering 101: top tools and framework resources
- Python
- R :statistical modelling and analysis using R language
- Hodoop(Hadoop Operations by Eric Sammer) : how they help in streaming the data. This is great to cluster and run a production environment.
- Spark(Spark: The Definitive Guide: Big Data Processing Made Simple) : Spark also includes clustering and monitoring, where one can process the data and execute them in real tim
- kafka : controlling the data flow
This infographic of Big Data tools(ver.2016)

tool에 대해서는 위에 기재한 것들이 핵심적이라고는 하지만, 일단 정확하게 어떤 역할을 하는지, 현재 회사에서 적용가능 범위인지? 아니면 현재는 다른 툴로 대체가 가능한 지를 살펴보고 공부하는 것이 맞는 순서인 듯 싶어서, 깊게 정리하지는 않았다.
'DE > Study' 카테고리의 다른 글
| 프로그래머스[데이터 엔지니어링 스타터 키트]필기 : ETL&Airflow (0) | 2021.08.28 |
|---|---|
| 프로그래머스[데이터 엔지니어링 스타터 키트]필기 : SQL (0) | 2021.08.23 |
| 프로그래머스[데이터 엔지니어링 스타터 키트] 필기 : AWS&Cloud&Redshift 간단한 개념 (1) | 2021.08.19 |
| 프로그래머스[데이터엔지니어링 스타터키트]필기 : 데이터팀과 데이터 엔지니어 (0) | 2021.08.10 |
| Data scientist 와 Data engineer란? (1) | 2021.07.25 |