약올림 프로젝트를 진행하면서 겪었던 에러를 바탕으로, 공부하고 썬나 개발스터디로 transaction에 대한 개념을 정리해보았다.
DB의 기초적인 개념일 수도 있긴 한데, 공부하는 동안 항상 놓쳤던 개념이 db transaction 이었다.
(그도 그럴 것이 1. database를 배울 때 언급된 개념이 아님 / 언급되지 않았어도 관련된 코드를 접해봤거나 관련 에러를 보았다면 개별적으로 공부해봤을 법도 하지만, 2. 토이프로젝트 단계에서 관련 코드를 예시로 본 적도 없고 에러가 난 적도 없다.)
그렇게 별도의 transaction 처리도 없이 별 다른 에러를 겪지 않고도 first project까지 완성, final project도 마무리 단계까지 잘 진행되었다. 그렇게 프로젝트 발표까지 2주 앞두고 큰 에러를 만나버렸다.

This Session’s transaction has been rolled back due to a previous exception during flush. To begin a new transaction with this Session, first issue Session.rollback()
백엔드 포지션으로써 코드 구현 뿐 아니라, 전체적인 서버 통신 테스트와 에러 해결도 진행하고 있었고, 마무리 즈음엔 배포 단계에서도 테스트를 해보고 있던 찰나에 해당 에러를 발견한 것이다.
코드 자체는 문제가 없었고, 이 에러가 한 번 나면 서버와 db 자체를 잠깐 쉬어줘야 했다.
(뭐 이런...실질적인 서비스라 생각하면 정말 말도안되는 서비스이다...이건 당장 고쳐야 겠다고 마음먹었다.)
처음엔 transaction이란 용어자체에 생소했었기 때문에, 에러 메시지 자체를 해석하지 못했고, 에러 메시지 하나하나를 구글링하면서
에러의 원인에 대해서 알게 되었고 해결법에 대해서도 접근할 수 있었다.
Transaction 이란?
개념적으로 transaction 이란 "데이터베이스의 상태를 변환시키는 하나의 논리적인 작업 단위를 구성하는 연산들의 집합" 이라고 한다.
좀 더 풀어서 정리하면
1. 트랜잭션은 데이터베이스 시스템에서 병행 제어 및 회복 작업 시 처리되는 작업의 논리적 단위이다.
2. 사용자가 시스템에 대한 서비스 요구 시 시스템이 응답하기 위한 상태 변환 과정의 작업단위이다.
3. 하나의 트랜잭션은 Commit되거나 Rollback된다.
server에서 db에 데이터 관련 요청을 할 때 날리는 하나의 쿼리를 transaction이라고 나만의 언어로 이해했다.
여기서 하나의 쿼리라 함은 하나의 db 테이블을 의미하는 것은 아니다. 한 번의 요청 시에 JOIN 등을 통해서 여러 테이블을 거쳐서 최종적인 하나의 데이터가 반환될 것이고, 이 하나의 요구가 transaction인 것이다.
즉, 내가 만나게 된 에러는, transaction에 관련된 개념을 프로젝트에 제대로 적용하지 않았고, 따라서 server와 db 사이의 작업에서 에러가 발생했던 것이다.
실제로 transaction을 처리해주지 않고 prod버전으로 배포했을 경우, db 통신 에러가 발생하면, A테이블에 update 완료 -> B테이블에 update 실패 -> C테이블 update 완료 / 이렇게 하나의 쿼리가 완료된 채로 실제 사용자에게 최종적으로 알려지게 된다.
(사용자의 포인트와 관련된 요청이라면, 포인트가 차감되어야 하는데 차감부분의 update가 실패된 상태로 사용자에게 차감됐다고 알려지는 것이다.)
그러면 transaction은 어떻게 처리해줄 수 있을까?
실제로 코드 자체는 간단하고, 그 방식도 다양하다. 기본적으로 commit과 rollback을 기억하고, 사용하는 데이터베이스 환경에 맞춰서 코드를 적절히 잘 적용하면 된다.
commit연산 : 한개의 논리적 단위(트랜잭션)에 대한 작업이 성공적으로 끝났고 데이터베이스가 다시 일관된 상태에 있을 때, 이 트랜2. 잭션이 행한 갱신 연산이 완료된 것을 트랜잭션 관리자에게 알려주는 연산
-> 즉, 내가 3개의 테이블을 건드리는 하나의 요청을 했는데, 실제로 이 요청들이 다 에러없이 완료되었다고 알려주는 연산인 것이다.
rollback연산 : 하나의 트랜잭션 처리가 비정상적으로 종료되어 데이터베이스의 일관성을 깨뜨렸을 때, 이 트랜잭션의 일부가 정상적으로 처리되었더라도 트랜잭션의 원자성을 구현하기 위해 이 트랜잭션이 행한 모든 연산을 취소(Undo)하는 연산
-> 이 개념이 중요했다. 위에서 언급한 일부의 테이블에 대해서는 정상적으로 처리되어도 다른 것에서 에러가 발생하면 이전 정상적인 처리까지 취소가 되는 것이다.
나의 경우 sqlAlchemy를 사용하고 있었기 때문에 sqlAlchemy내의 공식문서를 참고하여 코드를 작성했다.
전체적으로 try/except 구조로 서버 코드를 작성했으며, transaction이 잘 마무리 되어서 해당 쿼리가 완전히 다 실행완료 된것을 알리는 commit 코드를 try 문 마지막에 작성하고, 에러 발생시에 rollback 해주는 코드를 except코드에 작성했다.

이렇게 반복적으로 쓰이는 구조적인 코드는 좀 더 조직화해서 모듈처럼 가지고와서 쓸 수도 있을 것 같은데
(실제 썬나 서버 코드는 transaction 관련해서 하나의 코드에서 관리하고 이를 가져다 쓰는 개념으로 활용하고 있었다)
나도 좀 더 공부해 봐야겠다.
(역시 서버의 길은 멀고도 험난하고 공부할 것도 많구나!)
Transaction 성질
해당 블로그를 참고했다.
Atomicity(원자성) : All or Nothing이라고 기억하자.
- 트랜잭션의 연산은 데이터베이스에 모두 반영되든지 아니면 전혀 반영되지 않아야 한다.
- 트랜잭션 내의 모든 명령은 반드시 완벽히 수행되어야 하며, 모두가 완벽히 수행되지 않고 어느하나라도 오류가 발생하면 트랜잭션 전부가 취소되어야 한다.
Consistency(일관성)
- 트랜잭션이 그 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 변환한다.
- 시스템이 가지고 있는 고정요소는 트랜잭션 수행 전과 트랜잭션 수행 완료 후의 상태가 같아야 한다.
Isolation(독립성,격리성)
- 둘 이상의 트랜잭션이 동시에 병행 실행되는 경우 어느 하나의 트랜잭션 실행중에 다른 트랜잭션의 연산이 끼어들 수 없다.
- 수행중인 트랜잭션은 완전히 완료될 때까지 다른 트랜잭션에서 수행 결과를 참조할 수 없다.
Durablility(영속성,지속성)
- 성공적으로 완료된 트랜잭션의 결과는 시스템이 고장나더라도 영구적으로 반영되어야 한다.
Transaction Isolation level(격리수준)
위에서 언급된 transaction의 독립성이라는 성질과 관련해서 더 자세히 다뤄보고자 한다.
transaction의 isolation level은 실제 배포된 서비스가 여러 유저들에게 여러 요청을 받을 때 고려해야 하는 사항이다.
가령, 은행의 계좌거래와 관련된 경우를 살펴보자.
A라는 사람이 B라는 사람에게 계좌이체를 했다. 이는 일종의 B계좌의 DB에 update요청이 간 것이다. 이 때 거의 동시에 B 사람이 자신의 계좌를 조회(select) 하려 한다.
이렇게 다중 요청이 병행되어 즉 동시에 실행될 경우 필요한 개념이 isolaton level 인 것이다.
이 level은 실제로 여러 단계로 적용할 수 있다.
만약 level을 높이 설정한다면, 즉 격리성을 높인다면, update transaction이 실행완료 될때까지, select 관련된 요청은 잠시 lock 즉 멈추게 된다. 이때 조회하려는 사람은 로딩 창을 보게 될것이다. 하지만 이체된 결과를 정확히 볼 수 있을 것이다.
즉 격리성을 높인다면 속도면에서 느리지만, 안전하고 정확한 데이터 처리가 가능하다.
그러나 level이 낮다면? 위와 반대로, 이체가 되지 않은 상황에서도 조회가 되어서, 이체 된 부분이 반영되지 않은 상태로 조회가 될 것이다. 하지만 로딩창없이 바로 조회가 가능할 것이다. 즉 속도가 빠르지만, 데이터 처리에 있어서 좀 더 부정확하고 안전하지 못하다고 볼 수 있다.
Isolation level
-> 해당 블로그 참고
1. READ UNCOMMITTED
- 각 트랜잭션에서의 변경 내용이 COMMIT이나 ROLLBACK 여부에 상관 없이 다른 트랜잭션에서 값을 읽을 수 있다.
- 정합성에 문제가 많은 격리 수준이기 때문에 사용하지 않는 것을 권장한다.
- Commit이 되지 않는 상태지만 Update된 값을 다른 트랜잭션에서 읽을 수 있다.
2. READ COMMITTED
- RDB에서 대부분 기본적으로 사용되고 있는 격리 수준이다.
- Dirty Read(트랜잭션이 완료되지 않았는데도 다른 트랜잭션에서 볼 수 있게 되는 현상)와 같은 현상은 발생하지 않는다.
- 실제 테이블 값을 가져오는 것이 아니라 Undo 영역에 백업된 레코드에서 값을 가져온다.
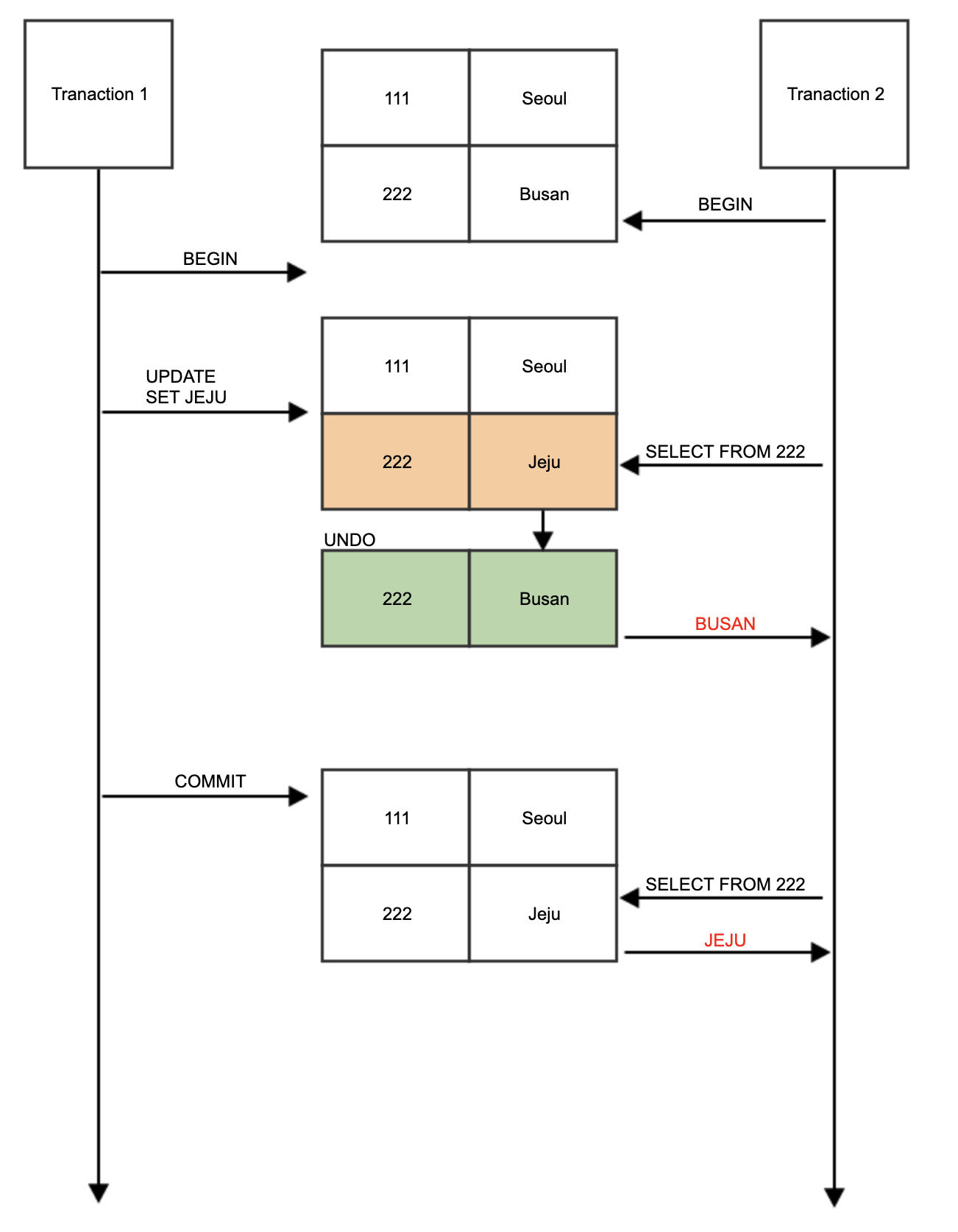
-> undo 즉, commit되어 db에 반영되지 않은 데이터가 select되어올 경우, 만약에 update transaction이 결국 commit 되지 않고, rollback되어 재실행 -> commit 될경우 select되는 값이 다르다. 위의 그림을 예시로 본다면 이런 격리수준에서는 transaction의 일관성에 어긋나게된다.
3. REPEATABLE READ
- MySQL에서는 트랜잭션마다 트랜잭션 ID를 부여하여 트랜잭션 ID보다 작은 트랜잭션 번호에서 변경한 것만 읽게 된다.
- Undo 공간에 백업해두고 실제 레코드 값을 변경한다.
- 백업된 데이터는 불필요하다고 판단하는 시점에 주기적으로 삭제한다.
- Undo에 백업된 레코드가 많아지면 MySQL 서버의 처리 성능이 떨어질 수 있다.
- PHANTOM READ
: 다른 트랜잭션에서 수행한 변경 작업에 의해 레코드가 보였다가 안 보였다가 하는 현상이 발생할 수 있다.

4. SERIALIZABLE
- 성능 측면에서는 동시 처리성능이 가장 낮다.
- SERIALIZABLE에서는 PHANTOM READ가 발생하지 않는다.하지만.. 데이터베이스에서 거의 사용되지 않는다.
- 가장 엄격한 격리 수준
격리수준이 무조건 높다고 해서 좋은 것은 아니다.
만약에 많은 트래픽을 빠르게 처리하는 것이 우선인 서비스의 경우, 특히 조회 처리가 잦은 경우에는 격리 수준을 높게 해버린다면,
몇 개의 update/create transaction 들로 인해서, select transaction이 lock으로 대기상태가 될 것이고 이 것이 계속 쌓인다면, 서비스에 지장을 줄 것이기 때문이다.
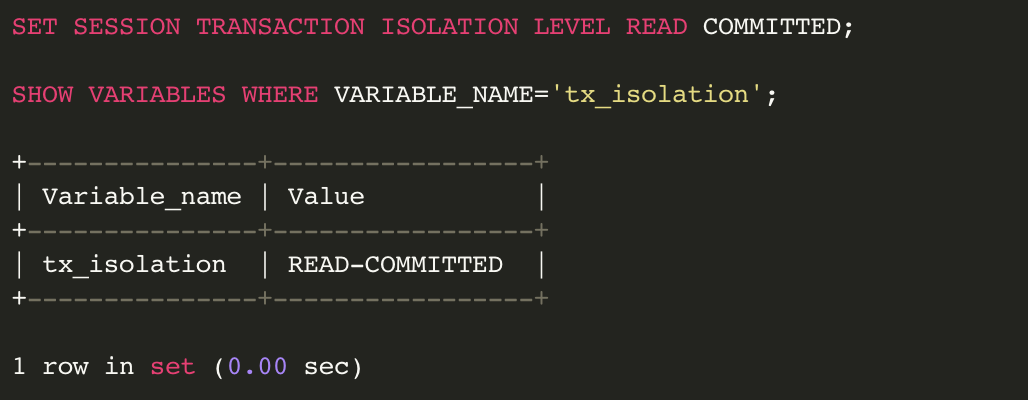
아래의 명령어로 현재의 격리수준을 확인할 수 있다.

또한 아래의 명령어로 격리수준을 조정할 수도 있다.
실제 transaction이 처리될 때, select 처리가 대기상태로 빠지는지 여부도 확인할 수 있다.
해당 부분은 MySQL의 홈페이지 공식문서 / 해당 블로그를 참고했다.
'CS STUDY > Database' 카테고리의 다른 글
| Partitioning(파티셔닝)과 Sharding(샤딩) (0) | 2022.08.21 |
|---|---|
| Database_Index(인덱스)란? (2) | 2022.03.24 |
| OLTP VS OLAP 기본비교 (0) | 2022.03.24 |
| Techniques to Scale RDBMS (0) | 2021.02.11 |
| Database_Application Cache 정리 (1) | 2021.02.07 |